This documentation is written from a Sys-Admin point of view as an addition to the official documentation, with the intent to demonstrate to IT Professionals how it compares to traditional solutions and Windows Server with a focus on Dell portfolio.
1 - 01. Operating System
Planning Operating System
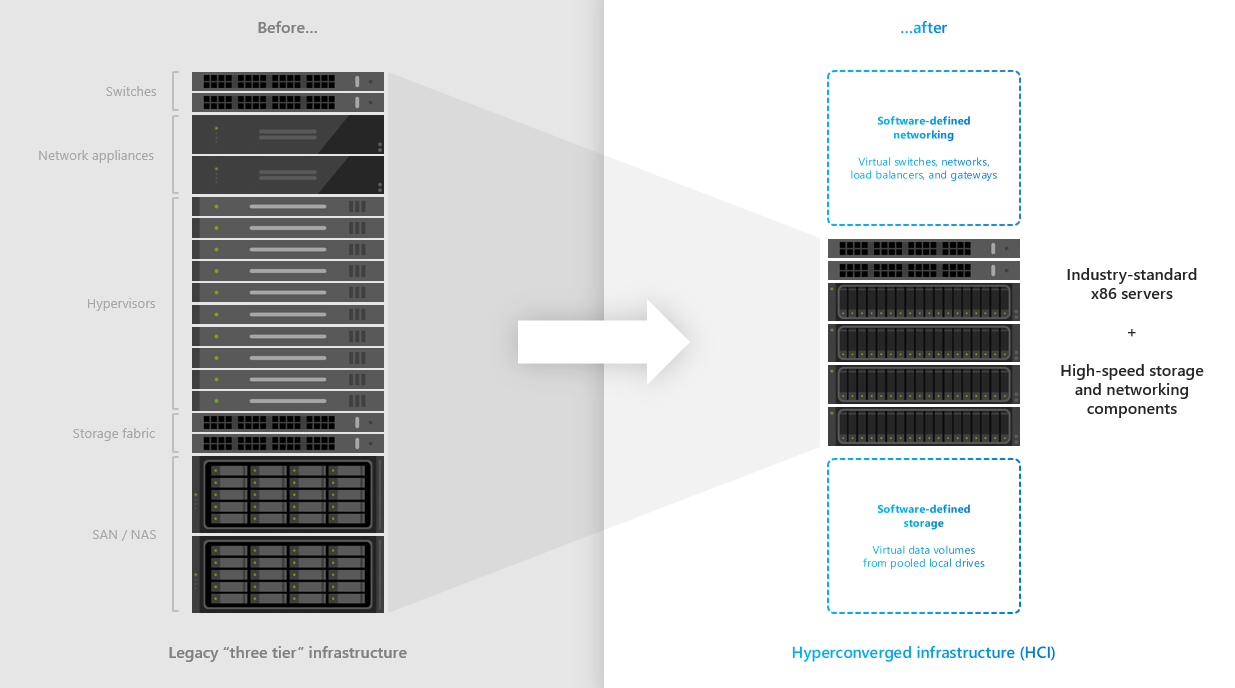
Storage Spaces Direct is technology, that is contained in both Azure Stack HCI OS and Windows Server Datacenter. It enables you to create hyperconverged cluster as there is a software storage bus, that enables every cluster node to access all physical disks in cluster.
Familiar for IT
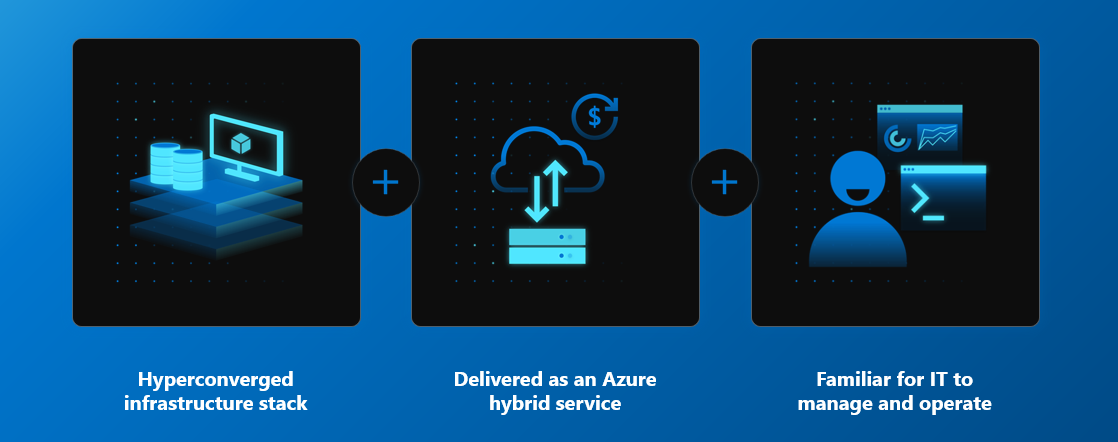
Both operating systems are easy to use for Windows Server admins that are familiar with failover clustering as both systems are using traditional technologies (Failover Clustering, Hyper-V) while domain joined. Therefore all tools (such as Server Manager, MMC and Windows Admin Center) can be used for management.
Hyper-Converged infrastructure stack
Both Azure Stack HCI and Windows Server are using the same technology that is well known since Windows Server 2016 - Storage Spaces Direct. Storage Spaces Direct enables all servers to see all disks from every node, therefore Storage Spaces stack can define resiliency and place data (slabs) in different fault domains. In this case nodes. Since all is happening in software, devices like high-speed NVMe disks can be used and shared using software stack using high-speed RDMA network adapters.
Delivered as an Azure hybrid service
The difference between both products is in way the service is consumed. With Windows Server, it’s traditional “buy and forget” model, where you can have operating system that is supported for 5+5 years (main+extended support) and you can pay upfront (OEM License, EA License …). Azure Stack HCI licensing can be dynamic. Imagine investing into the system where you have 40 cores/node, but you will initially use 16 cores only - you can easily configure number of cores in DELL systems using Openmanage Integration in Windows Admin Center and then pay only for how much you consume.
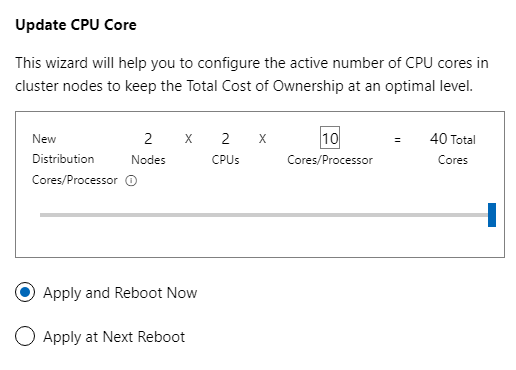

Additionally you can purchase Windows Server licenses as subscription add-on
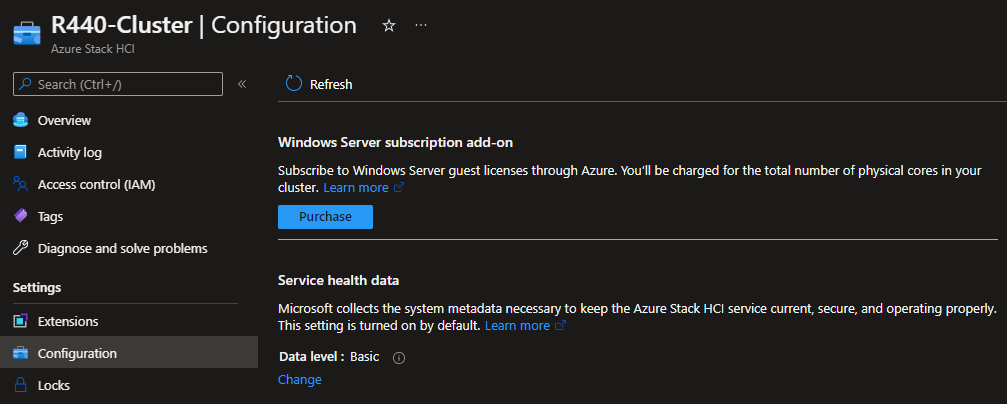
OS Lifecycle
The main difference is the way features are developed for each platform. Windows Server follows traditional development cycle (new version every 2.5-3years), while Azure Stack HCI follows cloud development cycle together with Windows Client OS (new version every year).
As result, new features are developed and delivered into Azure Stack HCI OS every year.
While both Windows Server and Azure Stack HCI operating systems can run on virtualization host, going forward the main focus will be Azure Stack HCI OS for hosts and Windows Server for guest workloads. For more information see the video below.
Comparison of Azure Stack HCI and Windows Server is available in official docs.

2 - 02. Supporting Infrastructure
Planning Supporting Infrastructure
There are several deployment sizes. Let’s split it into three main categories. While all three categories can be managed just with one management machine and PowerShell, with more clusters or racks, management of the infrastructure can be very complex task. We can assume, that with Azure Stack HCI hybrid capabilities, will more infrastructure move into cloud.
In many cases we hear, that due to security, DHCP is not allowed in server subnet. Limiting what server can receive IP address can be done with MAC Address Filtering.
Management infrastructure can be deployed in separate domain from hosted virtual machines to further increase security.
Management machine can be also deployed as Privileged Access Workstation.
Minimum infrastructure
The minimum components are Domain Controller and Management machine. Management machine can be Windows 10 or Windows Server at least the same version as the managed server (for example Windows 10 1809 and newer can manage Windows Server 2019). DHCP server can significantly help as managed servers can receive IP address. That means you can manage them remotely without logging into servers to configure static IP, but it’s not mandatory.
Windows Admin Center can be installed on Admin Workstation. From there, infrastructure can be managed using Windows Admin Center, PowerShell or legacy remote management tools (such as mmc).
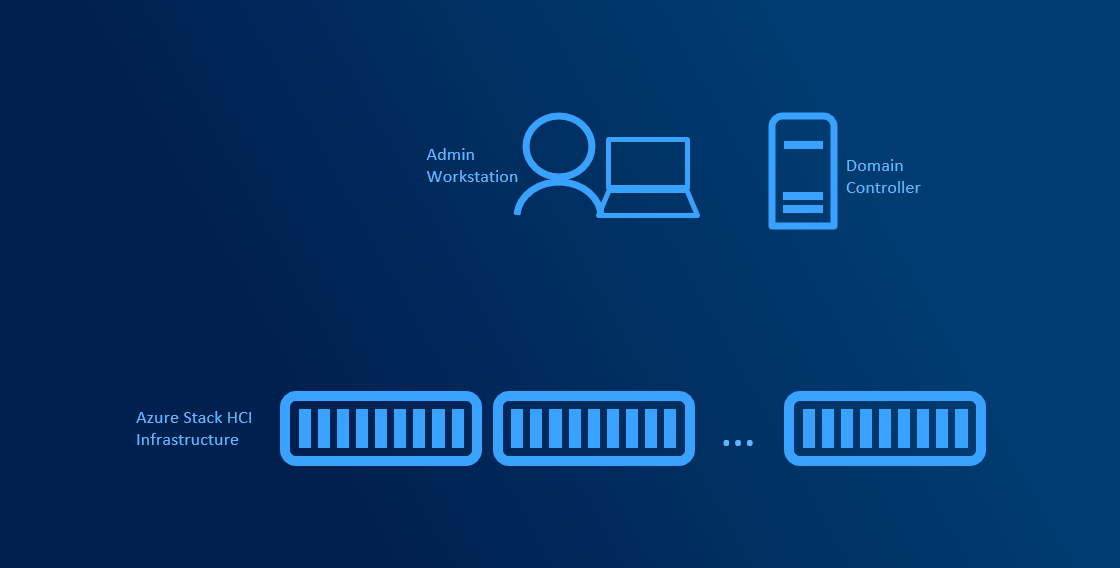
Medium infrastructure
Medium infrastructure assumes you have multiple administrators and/or multiple clusters in your environment. Another servers dedicated for management can be introduced to help with management centralization or automating management.
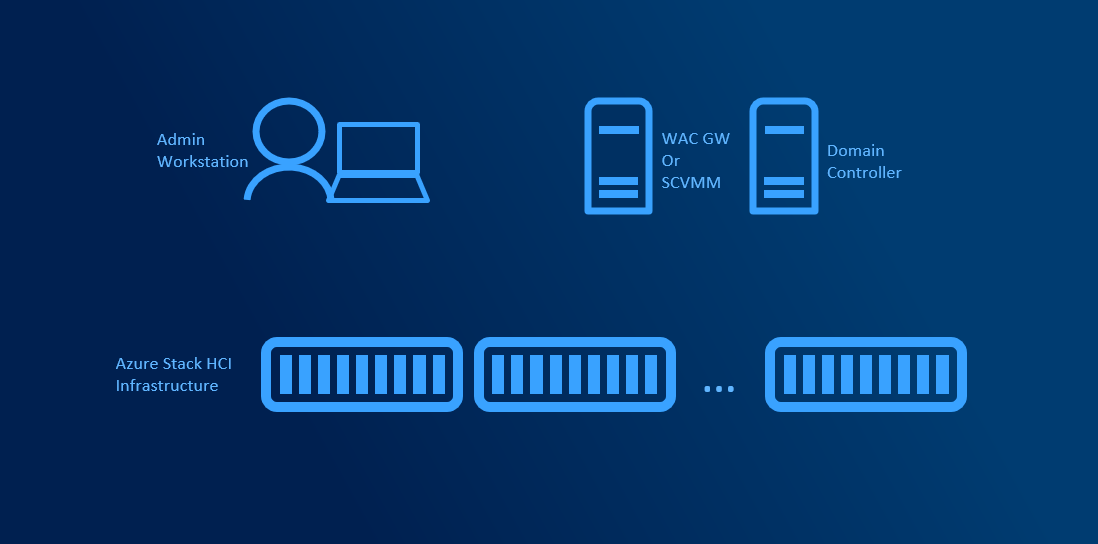
Large Scale infrastructure
Large Infrastructure assumes that you have more clusters spanning multiple racks or even sites. To help with bare-metal deployment, network management, patch management is SCVMM essential. Supporting roles (WSUS, WDS, Library servers) managed by SCVMM can be deployed across multiple servers. SCVMM supports deployment in HA Mode (Active-Passive) with SQL server Always On. DHCP is mandatory for bare-metal deployment as during PXE boot, server needs to obtain IP Address.
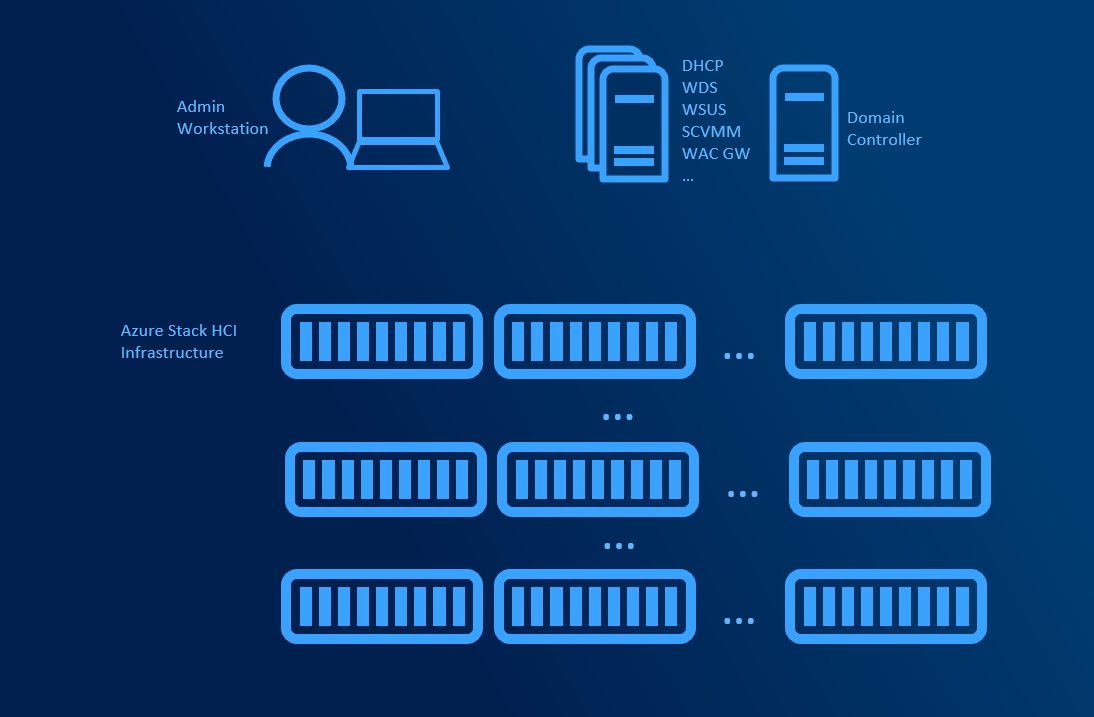
3 - 03. Planning Deployment Models and Workloads
Planning Deployment Models and Workloads
Depending on size, usage and complexity of the environment you need to design what deployment model for Azure Stack HCI you want to choose. HyperConvered deployment is the simplest. It’s great for it’s simplicity, however for specialized tasks (like CPU/RAM consuming Virtual Machines) with moderate/high storage workload it might be more effective to split CPU/RAM intensive workload and storage into Converged deployment.
HyperConverged deployments
HyperConverged deployments can be small as 2 nodes connected directly with network cable and grow to multi-PB 16 node clusters (unlike traditional clusters, where limit is 64 nodes). Minimum requirements are described in hardware requirements doc.
Simplicity is the main benefit in this deployment model. All hardware is standardized and from one vendor, therefore there is a high chance that there are hundreds of customers with exact same configuration. This significantly helps with troubleshooting. There are no extra hops compared to SAN, where some IOs are going over FC infrastructure and some over LAN (CSV redirection).
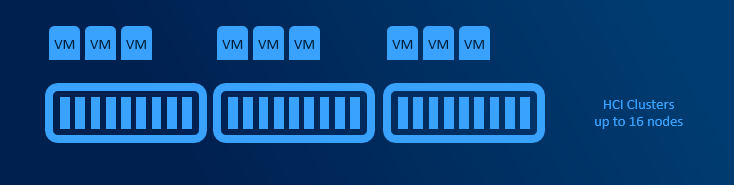
Converged deployments
Converged deployments have separate AzSHCI cluster with Scale-Out File Server role installed. Multiple compute clusters (up to 64 nodes each) can access single Scale-Out File Server. This design allows to use both Datacenter and Standard licenses for Compute Clusters.
This design adds some complexity as Virtual Machines are accessing its storage over network. Main benefit is, that one VM consuming all CPU cycles will not affect other VMs because of degraded storage performance and also you can scale storage independently from RAM and CPU (if you run out of cpu, no need to buy server loaded with storage). This design allows higher density, better deduplication job schedule and decreased east-west traffic (as VMs are pointed to it’s CSV owner node using Witness Service or new SMB Connections move on connect).
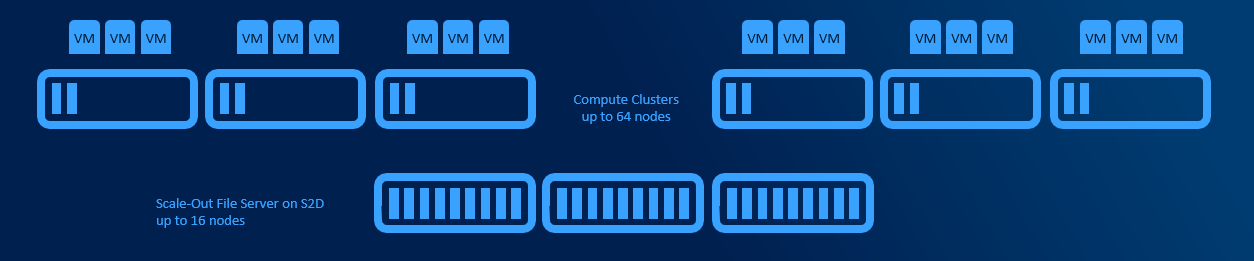
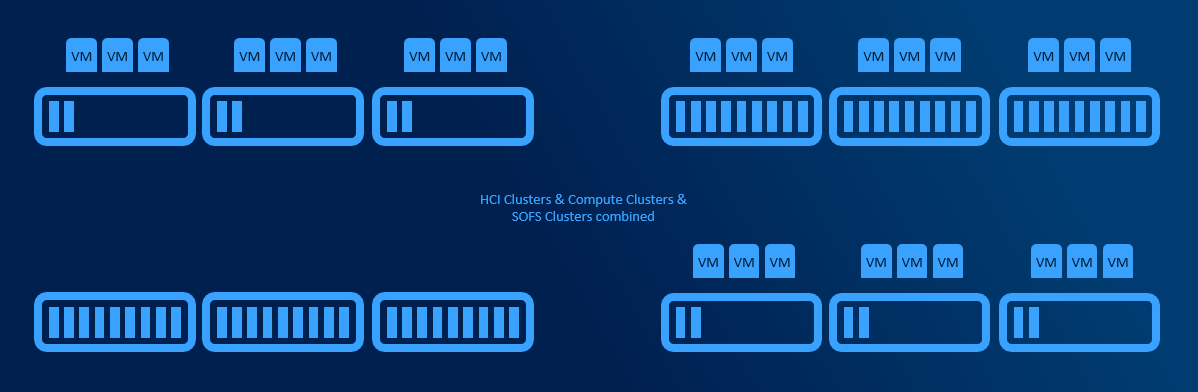
Cluster Sets
If multiple clusters are using multiple Scale-Out FileServers or even if multiple HyperConverged clusters are present, cluster sets helps putting all clusters under one namespace and allows to define fault domains. When VM is created, fault domain can be used (instead of pointing VM to specific node/cluster).
Technically all VMs are located on SOFS share that is presented using DFS-N namespace. This namespace is hosted on Management cluster that does not need any shared storage as all configuration data are in registry.
User Profile Disks host
Azure Stack HCI can also host user profile disks (UPDs). Since UPD is VHD (both native Windows Server functionality and FSLogix), Scale-Out File Server can be used as workload pattern is the same as for Virtual Machines. However it might make sense to use fileserver hosted Virtual Machine.
SQL
There are multiple ways to deploy SQL Server on Azure Stack HCI cluster. But in the end there are two main - Deploying a SQL Server in a Virtual Machine, or in AKS (Azure Kubernetes Service) as SQL Managed instance.
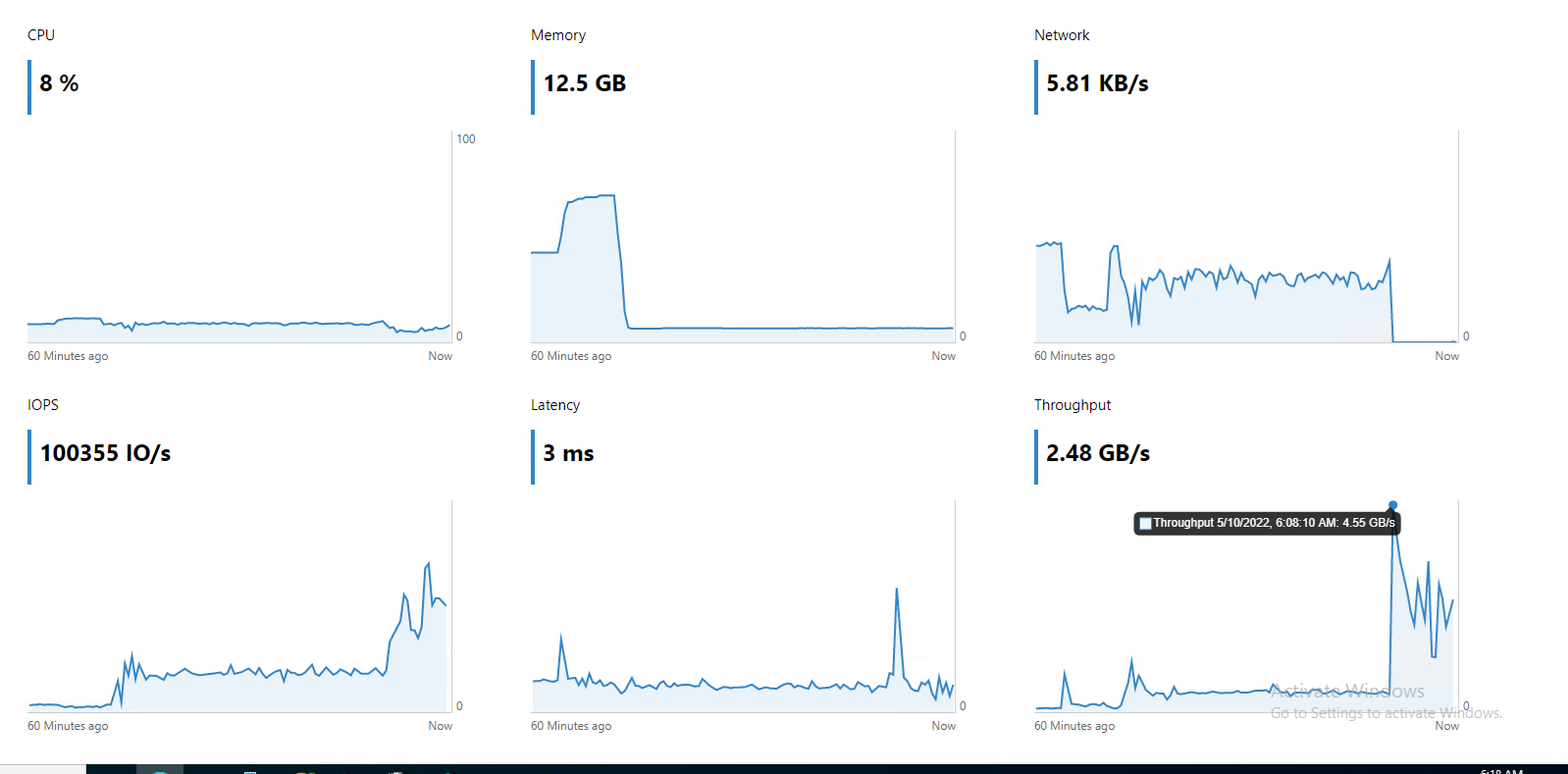
SQL Performance in one Virtual Machine (out of 40 on 4 node cluster) running SQL workload (database forced to read from disk)
Kubernetes
TBD
VDI
TBD
4 - 04. Planning Network Architecture
Planning Network Architecture
To correctly plan infrastructure design is key part in Azure Stack HCI planning. With incorrect configuration, the infrastructure might not be reliable under load. Depending on scale more complex solution might make sense to better control traffic.
In general there are two types of traffic - East-West and North-South. East-West is handled by SMB protocol (all traffic generated by Storage Bus Layer and Live Migration). North-South is mostly traffic generated by Virtual Machines.
Physicals switches should be configured with native VLAN for management traffic. This will significantly help as without configuring VLAN on physical host, you will be able to communicate over network. This helps bare metal deployment and also helps with Virtual Switch creation when management network is using vNIC.

In text above were several abbreviations used. Let’s explain few.
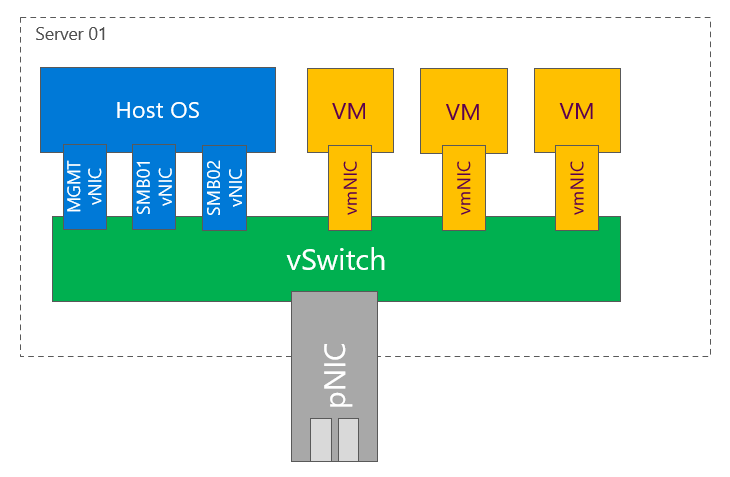
- pSwitch = Physical Switch. It’s your Top of the rack Switch (TOR)
- vSwitch = Virtual Switch. It is switch, that is created on host using New-VMSwitch command
- vNIC = Virtual Network Adapter. It is a vNIC that is connected to Management OS (to parent partition). This is the NIC that is usually used for management or SMB.
- vmNIC = Virtual Machine Network Adapter. This is a vNIC connected to Virtual Machine.
Topology design
Single subnet
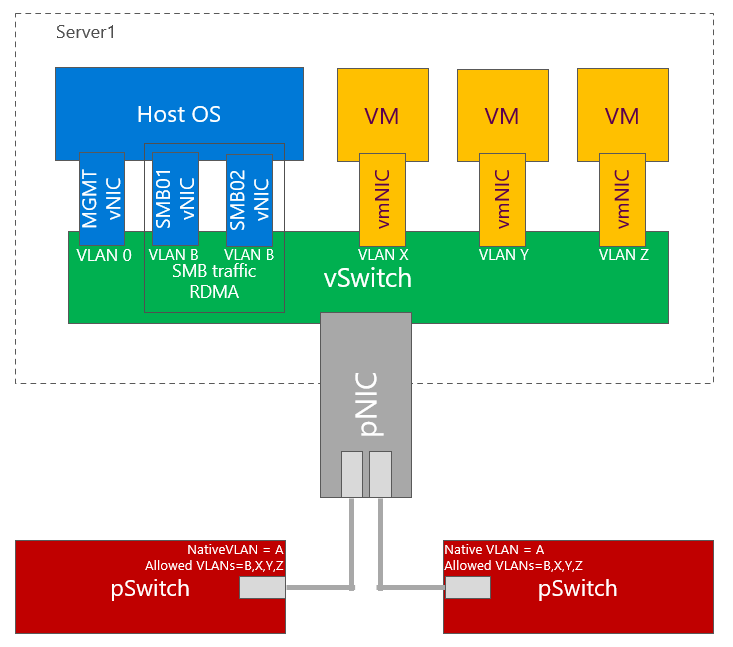
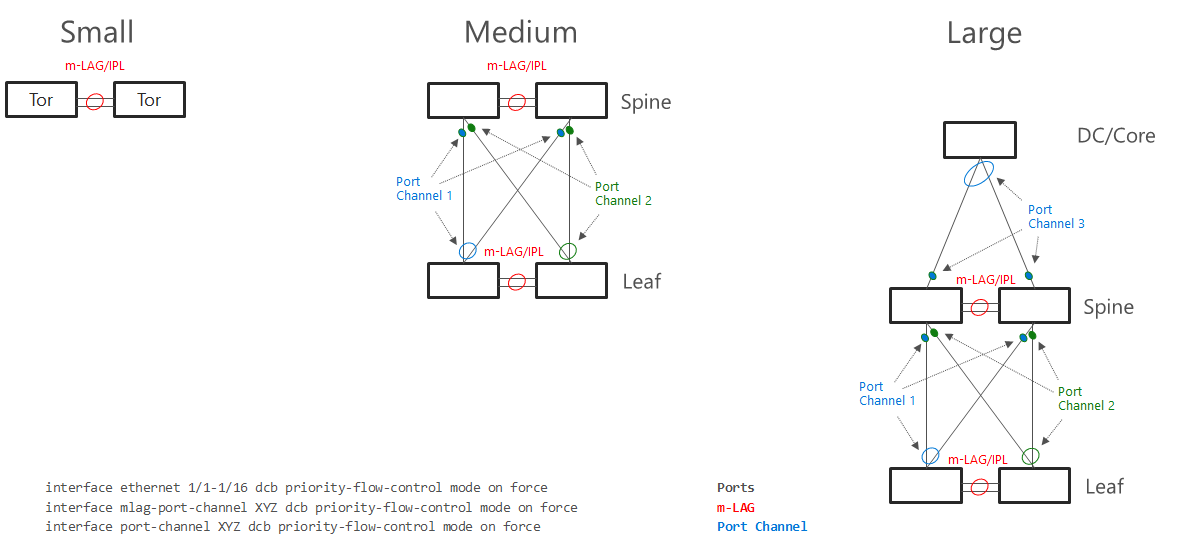
In Windows Server 2016 was support for single subnet multichannel in cluster support added. This allows to configure only single subnet for multiple network adapters dedicated for SMB Traffic. It is recommended topology design for smaller deployments, where interconnection between TOR switches can handle at least 50% network throughput generated by nodes (as there is 50% chance, that traffic travel using switch interconnect - m-LAG). For example with 4 nodes each node 2 times 25Gbps connections, you should have at least 100Gbps connection between TOR switches.
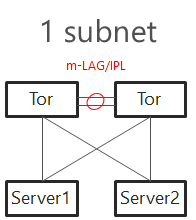
TOR Switches will be configured with Trunk and native (access) VLAN for management.
Two subnets
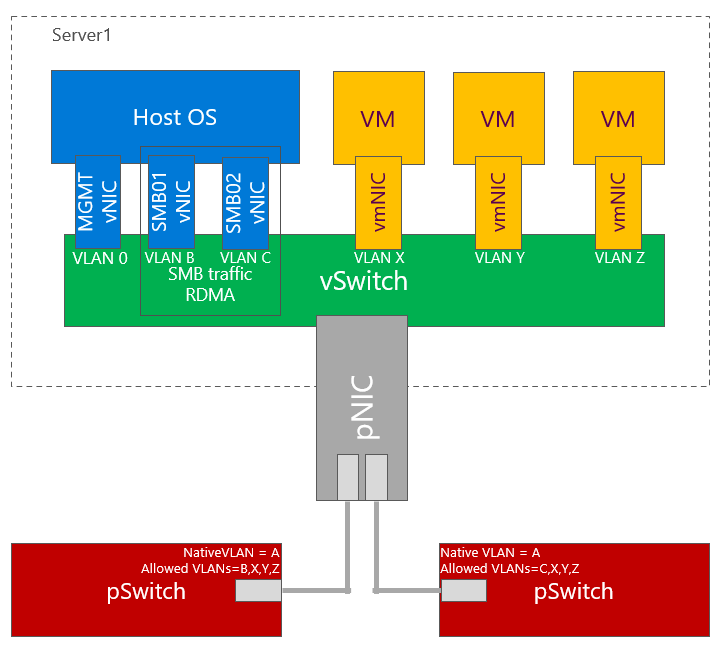
With increased number of nodes, there might be a congestion in TOR switches interconnect. Also in case congestion will happen and pause frame will be sent, both switches will be paused. To mitigate both, you can configure 2 subnets - each network switch will host separate subnet. This also brings one benefit - in converged setup if connection fails, it will be visible in failover cluster manager. m-LAG is optional if switches are dedicated for East-West (SMB) only. In this case as there is no traffic generated from SMB multichannel as each SMB adapter is in different subnet. In case VMs or any other traffic is using it, m-LAG is required.
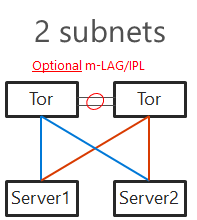
TOR Switches will be configured with Trunk and native (access) VLAN for management with one slight difference from single subnet. Each subnet for SMB traffic will have it’s own VLAN. This will also help discover disconnected physical connections (https://youtu.be/JxKMSqnGwKw?t=204).
Note: Two subnet deployment is being now standard. Same approach is used when NetworkATC is deployed.
Direct connections (Switchless)
In Windows Server 2019 you can connect all nodes in mesh mode. In case you have 2 nodes, it’s just one connection. With 3 nodes, it’s 3 interconnects. With 5 nodes, it whoops to 10. For 2 or 3 nodes design it makes sense to use 2 connections between 2 nodes in case one link goes down (for example cable failure). This would result traffic going over slower connection (like 1Gb if North-South is using Gigabit network links). Dell supports up to 4 nodes in switchless configuration.
The math is simple. With 5 nodes its 4+3+2+1=10. Each connection requires separate subnet.
# Calculation for number of connections
$NumberOfNodes = 5
(1..($NumberOfNodes - 1) | Measure-Object -Sum).Sum

RDMA Protocols
RDMA is not required for Azure Stack HCI, but it is highly recommended. It has lower latency as traffic is using hardware data path (application can send data directly to hardware using DMA).
Great resources explaining benefit of RDMA:
There are multiple flavors of RDMA. The most used in Azure Stack HCI are RoCEv2 and iWARP. Infiniband can be used also, but just for SMB traffic (NICs cannot be connected to vSwitch).
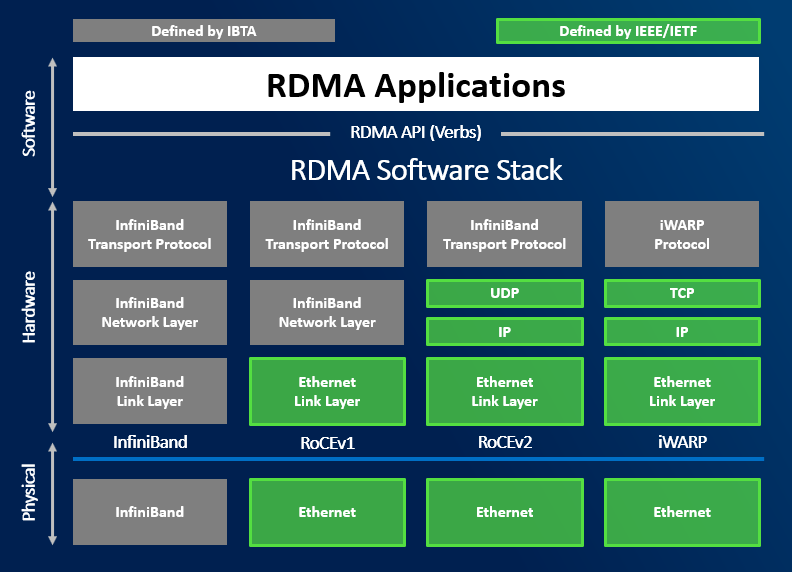
iWARP
iWARP is using TCP for transport. This is bit easier to configure as it uses TCP for Congestion Control. Configuring DCB/ETS is not mandatory. For larger deployments it is recommended as traffic can be prioritized.
Some network vendors require to configure Jumbo Frames to 9014.
RoCE
RoCE is using UDP for transport. It is mandatory to enable DCB (PFC/ETS) and ECN on both physical NICs and physical network infrastructure.
If congestion control mechanisms are not correctly implemented, it can lead to huge retransmits. This can lead to infrastructure instabilities and storage disconnections. It is crucial to configure this correctly.
where DCB needs to be configured
Virtual Switch and Virtual Network adapters
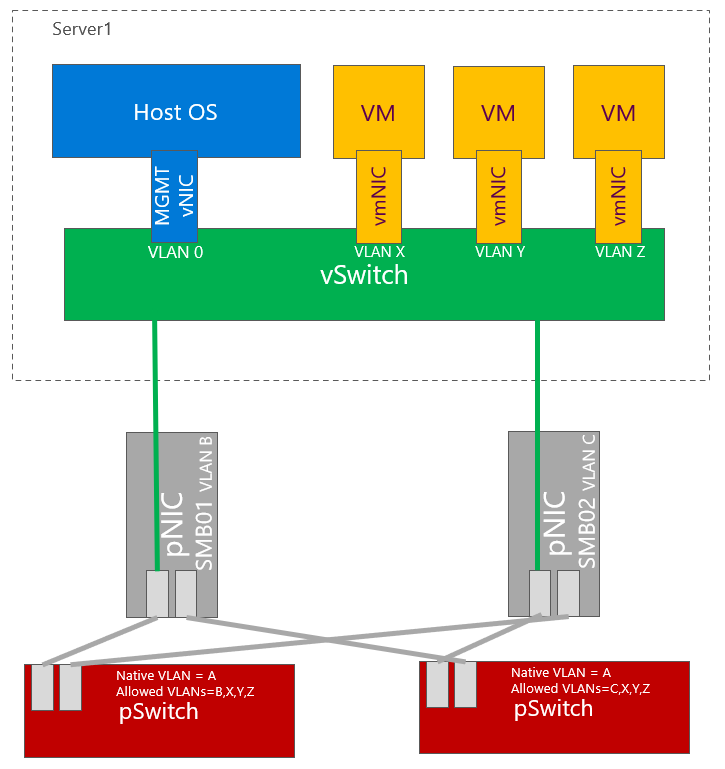
Converged Design
This design is most common as it is simplest and requires just two ports. Since RDMA can be enabled on vNICs. In the example below is one VLAN used for SMB vNICs. As mentioned in above text, you may consider using two VLANs and two subnets for SMB vNICs to control traffic flow as it is becoming standard.
Converged design also makes best use of capacity (let’s say you have 4x25Gbps NICs), you can then use up to 100Gbps capacity for storage or Virtual Machines, while using latest technology such as VMMQ.
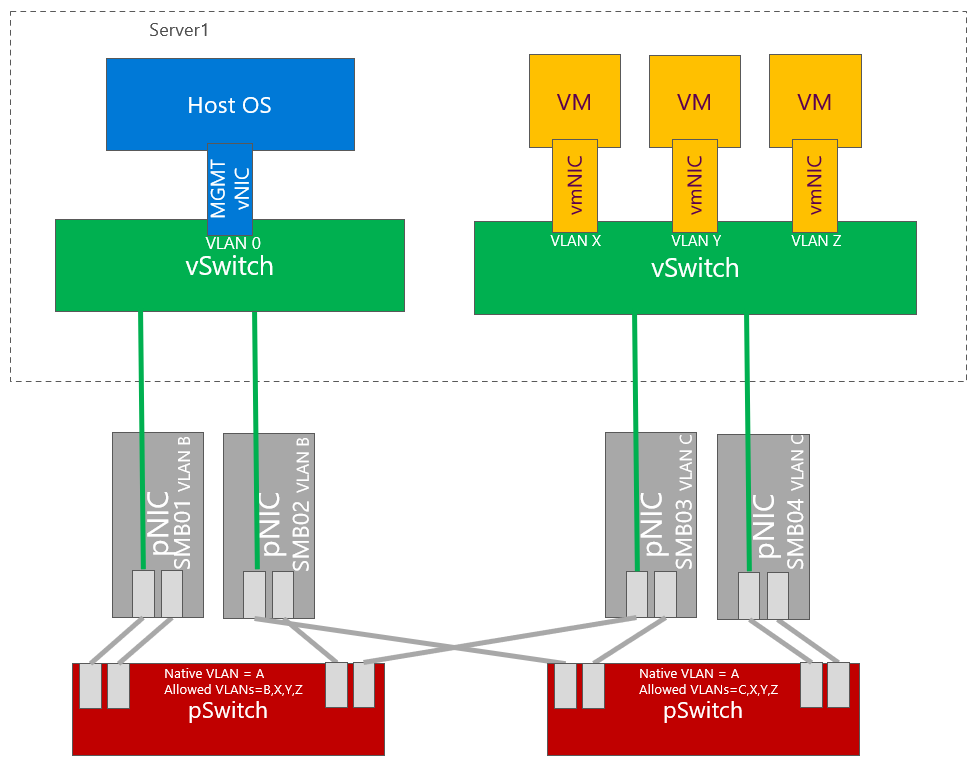
Dedicated NICs for East-West traffic
Some customers prefer to dedicate physical network adapters for east west traffic. In example below all physical ports on physical switch are configured the same (for simplicity). Also just two physical switches are used. You can also have dedicated switches for east-west traffic (for SMB). If DCB is configured, VLANs are mandatory for SMB adapters. In example below one VLAN for SMB is used. Two VLANs and two subnets can be used to better control traffic.
Dedicated NICs for East-West traffic and management
Some customers even prefer to have dedicated network cards (ports) for management. One of the reason can be customers requirements to have dedicated physical switches for management.
Network adapters hardware
Network adapters that support all modern features such as VMMQ or SDN offloading are in Hardware Compatibility list listed as Software-Defined Data Center (SDDC) Premium Additional Qualifier. For more information about Hardware Certification for Azure Stack HCI you can read this 2 part blog - part1, part2.

5 - 05. Storage Capacity Planning
Planning capacity
Capacity reserve
When disk failure happens, it is necessary to have some capacity reserve to have immediate capacity to rebuild to. So for example if one disk in one node disconnects, there will be reserved capacity to have required number of copies (2 copies in 2-way mirror, 3 copies in 3-way mirror).
It is recommended to have largest disk capacity in each node not occupied - reserved. For calculation you can use http://aka.ms/s2dcalc. It is not necessary to mark disk as “reserved” or anything like that as it all about not consuming capacity of one disk.
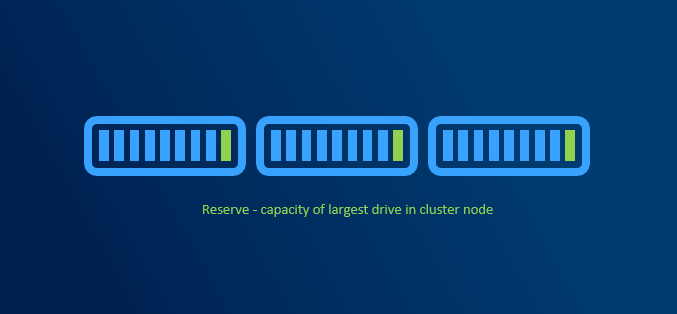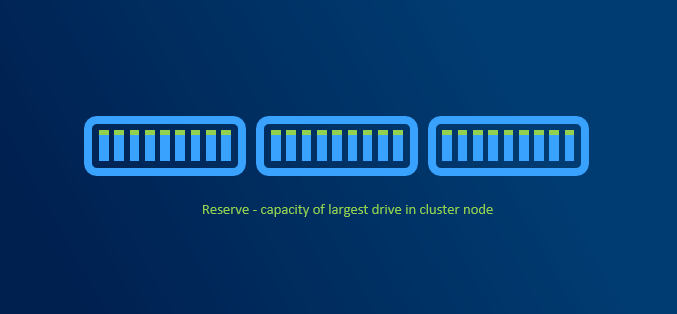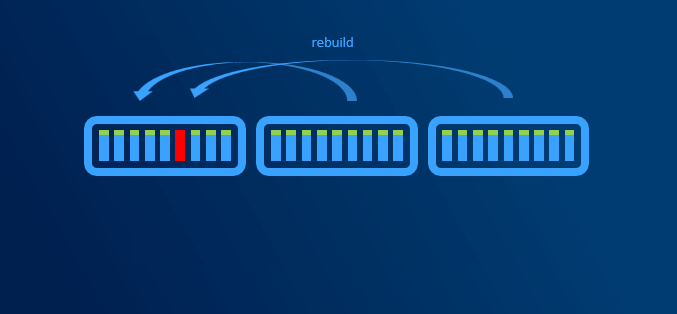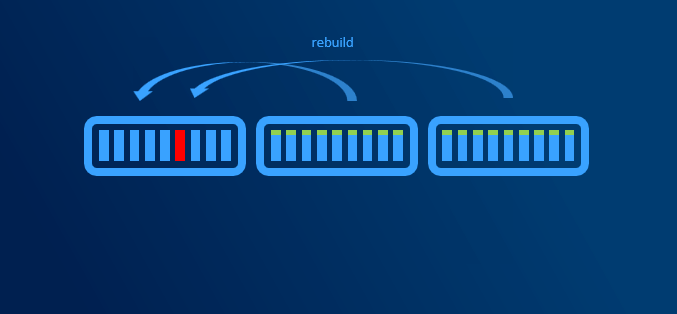
Since we regular maintenance is required (security patches), reboot might be necessary. Or for example if any hardware upgrade is done (for example increasing RAM), node might need to be put into maintenance mode or even shut down. If VMs are required to run, then there has to be capacity (RAM) to keep VMs running on rest of the nodes.
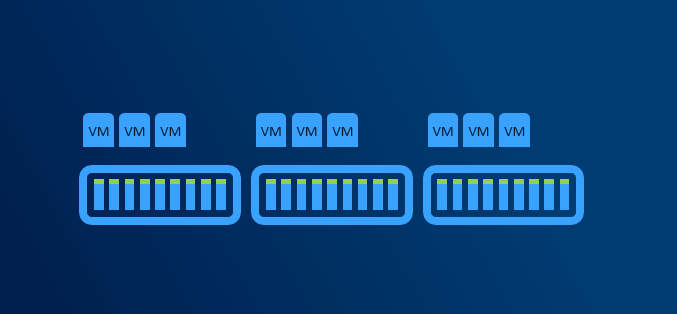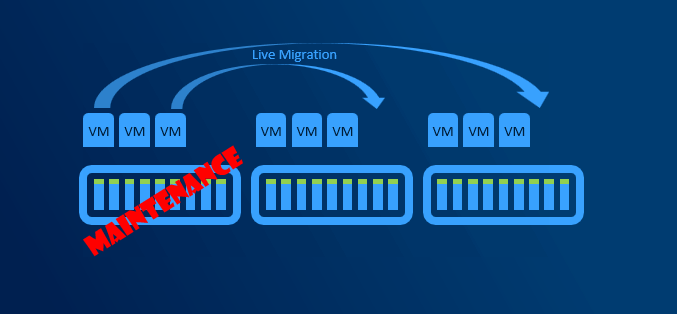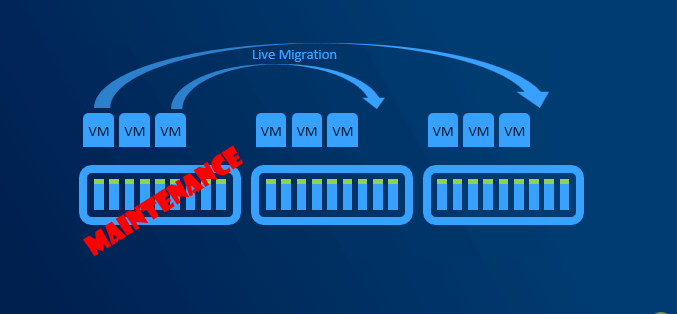
With more than 5 nodes it might make sense to reserve entire node. You will have capacity for VMs when node in maintenance, and you will be also able to rebuild if one node is completely lost - assuming all disks damaged (which is usually unlikely to happen as usually just one component fails and can be replaced withing service agreement).
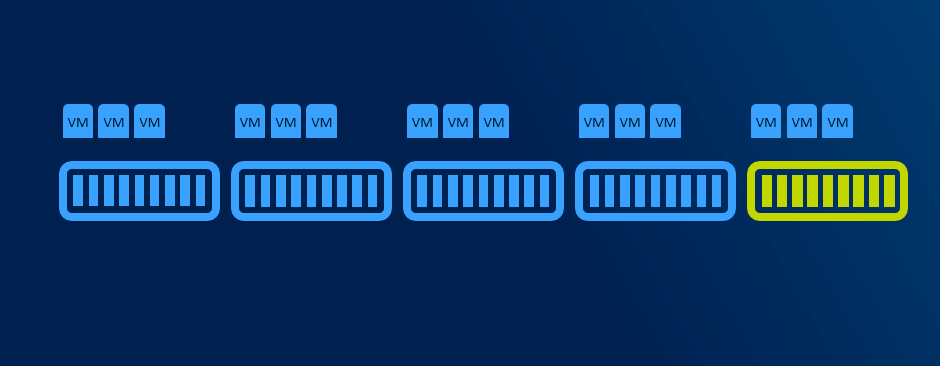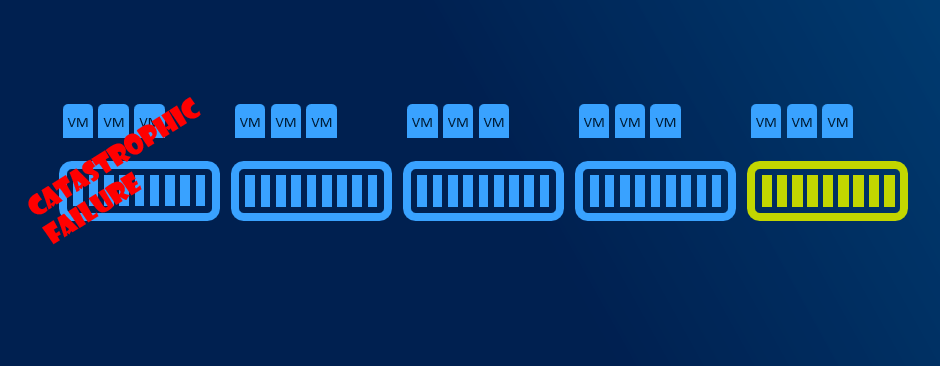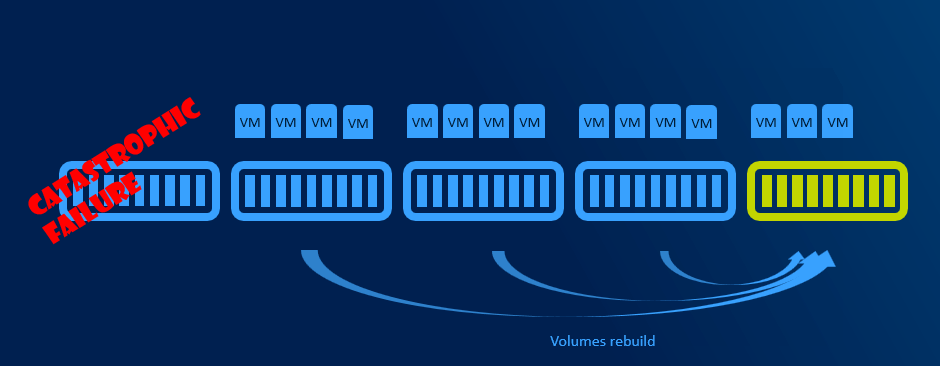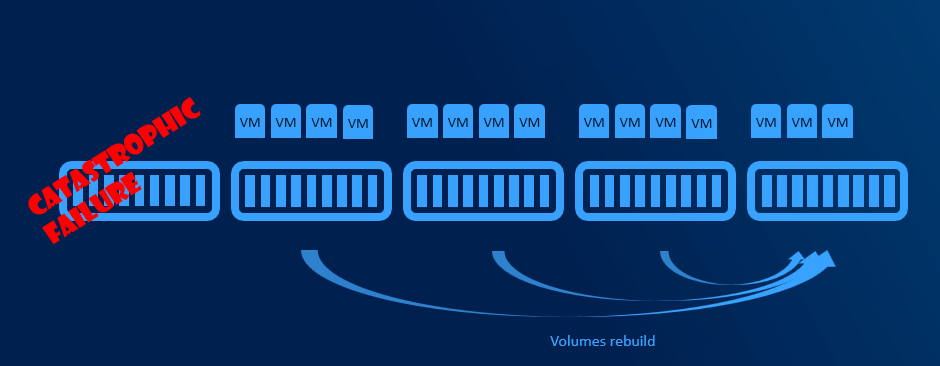
Resiliency options
Mirror (two-way and three-way)
Two-way mirroring writes two copies of everything. Its storage efficiency is 50% - to write 1TB of data, you need at least 2TB of physical storage capacity. Likewise, you need at least two fault domains. By default, fault domain is Storage Scale Unit (which translates into server node). Fault domain can be also Chassis or Rack. Therefore if you have two node cluster, two-way mirroring will be used.
With three-way mirror, the storage efficiency is 33.3% - to write 1TB of data, you need at least 3TB of physical storage capacity. Likewise you need to have at least three fault domains. If you have 3 nodes, by default three-way mirror will be used.
Dual-parity
Dual parity implements Reed-Solomon error-correcting codes to keep two bitwise parity symbols, thereby providing the same fault tolerance as three-way mirroring (i.e. up to two failures at once), but with better storage efficiency. It most closely resembles RAID-6. To use dual parity, you need at least four hardware fault domains – with Storage Spaces Direct, that means four servers. At that scale, the storage efficiency is 50% – to store 2 TB of data, you need 4 TB of physical storage capacity.
With increasing number of fault domains (nodes), local reconstruction codes, or LRC can be used. LRC can decrease rebuild times as only local (local group) parity can be used to rebuild data (there is one local and one global parity in dataset).
Mirror-Accelerated Parity
Spaces Direct volume can be part mirror and part parity. Writes land first in the mirrored portion and are gradually moved into the parity portion later. Effectively, this is using mirroring to accelerate erasure coding.
To mix three-way mirror and dual parity, you need at least four fault domains, meaning four servers.
The storage efficiency of mirror-accelerated parity is in between what you’d get from using all mirror or all parity, and depends on the proportions you choose
Recommended reading
Scoped volumes
With increasing number of nodes it might be useful to put data only on selected nodes to better control what data will be accessible in case of failure of certain nodes. With scoped volumes, volumes can system tolerate more than 2 nodes failure while keeping volumes online.

Cache drives
Faster media can be used as cache. If HDDs are used, cache devices are mandatory. Cache drives do not contribute to capacity.
For more information about cache visit docs
6 - 06. Hardware
Planning hardware
CPU
In hyperconverged systems, CPU handles both VMs and Storage. Rule of thumb is that each logical processor can handle ~60MiB IOPS. Let’s calculate an exaple: four node cluster, each node two twelve-core CPUs results. If we consider 4k IOPS, each LP can handle ~15k IOPS. With 4 nodes, 24 LPs each it results in ~1.5M IOPS. All assuming that CPU is used for IO operations only.
Storage devices
In general, there are two kinds of devices - spinning media and solid state media disks. We all know this story as it’s been some time we upgraded our PCs with SSDs and we were able to see the significant latency drop. There are two factors though - type of media (HDD or SSD) and type of bus (SATA, SAS, NVMe or Storage Class Memory -SCM).
HDD mediatype is always using SATA or SAS. And this type of bus was more than enough for it’s purpose. With introduction of SSD mediatype, SATA/SAS started to show it’s limitation. Namely with SATA/SAS you will utilize 100% of your CPU and you will not be able to reach more than ~300k IOPS. It’s because SATA/SAS was designed for spinning media and also one controller connects multiple devices to one PCIe connection. NVMe was designed from scratch for low latency and parallelism and has dedicated connection to PCIe. Therefore NAND NVMe outperforms NAND SATA/SAS SSD drive.
Another significant leap was introduction of Intel Optane SSD, that introduces even lower latencies than NAND SSDs. And since in Optane media is bit addressable, there is no garbage to collect (on NAND SSD you erase only in blocks with negative performance impact).
Important piece when selecting storage devices is, that if you consider SSD+HDD combination, all heavy lifting will end up in one SATA/SAS controller connected into one PCIe slot. Therefore it’s recommended to consider using NVMe instead, as each NVMe will have its PCIe line.

Network cards
There are several considerations when talking about network cards.
Network Interface Speed
Network Cards are coming in speeds ranging from 1Gbps to 200Gbps. While hyperconverged infrastructure will work with 1Gbps, the performance will be limited. The requirement is to have at least one 10Gbps port per server. However it’s recommended to have at least 2x10Gbps with RDMA enabled.
| Mediatype | Recommended NICs |
|---|---|
| SSD as cache or SSD all-flash | 2×10 Gbps or 2x25Gbps |
| NVMe as cache | 2-4×25Gbps or 2×100Gbps |
| NVMe all-flash | 2-4×25Gbps or 2×100Gbps |
| Optane as cache | 2-4×100 Gbps or 2×200Gbps |
Use of RDMA
When RDMA is enabled, it will bypass networking stack and DMA directly into memory of NIC. This will significantly reduce CPU overhead. While RDMA is not mandatory, it’s highly recommended for Azure Stack HCI as it will leave more CPU for Virtual Machines and Storage.
RDMA protocol
There are two flavors of RDMA. iWARP (TCP/IP) and RoCE (UDP). The main difference a need of lossless infrastructure for RoCE as when switch is loaded and starts dropping packets, it cannot prioritize or even notify infrastructure to stop sending packets if DCB/PFC/ETS is not configured. When packet is dropped on UDP, large retransmit needs to happen and this cause even higher load on switches. Retransmit will also happen on TCP/IP, but significantly smaller. It is still recommended to configure PFC/ETS on both if possible - in case switch needs to notify infrastructure to stop sending packets.
Network infrastructure
Reliable, low latency infrastructure is a must for reliable function of Converged and HyperConverged infrastructure. As already covered above, DCB (PFC nad ETS) is recommended for iWARP and required for RoCE. There is also alternative - starting Windows Server 2019, direct connection is supported. As you can see, it does not make sense to have more than 5 nodes in the cluster (with increasing number of interconnects)
| Number of nodes | Number of direct connections |
|---|---|
| 2 | 1 |
| 3 | 3 |
| 4 | 6 |
| 5 | 10 |
Note: Dell supports up to 4 nodes in switchless configuration
Hardware certification programme
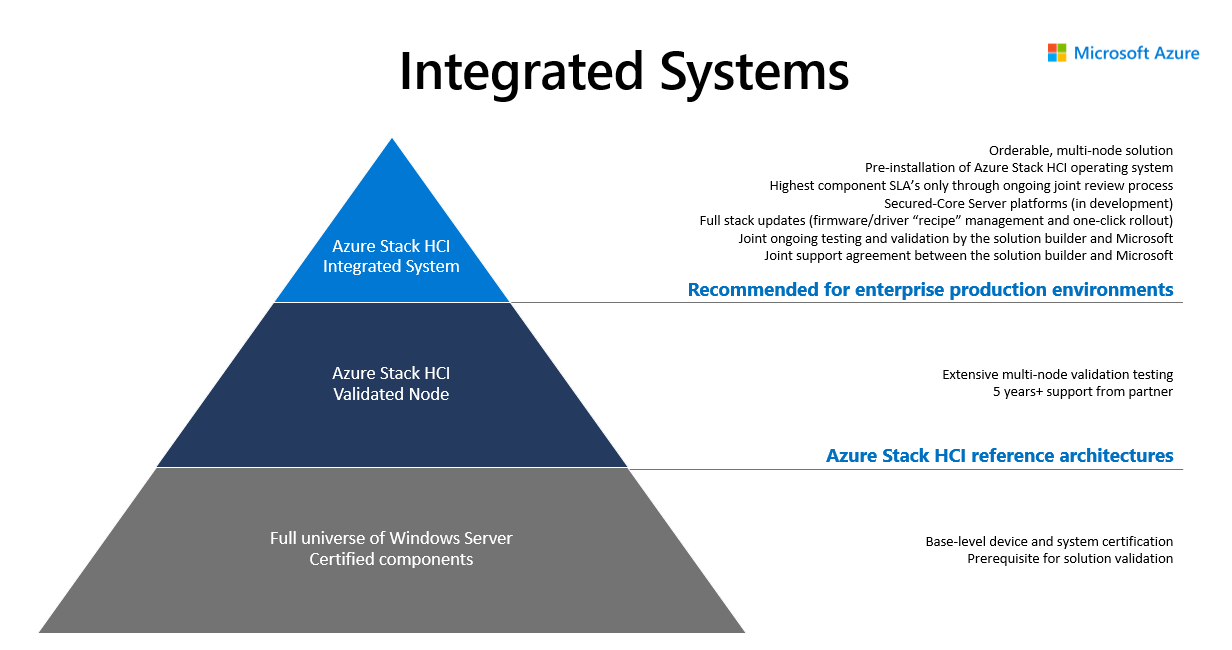
It is very important to follow validated hardware path. This way you can avoid ghost hunting when single component will misbehave due to firmware or even hardware not being able to handle load under high pressure. There is very good blog summarizing importance of validated hardware part1 part2. Validated solutions are available in Azure Stack HCI Catalog. For Azure Stack HCI you can also consider Integrated System which includes the Azure Stack HCI operating system pre-installed as well as partner extensions for driver and firmware updates.
Note: Dell sells only Integrated Systems as Microsoft highly recommend those over just verified solutions.