Use Cases
CSM for Resiliency is primarily designed to detect pod failures due to some kind of node failure or node communication failure. The diagram below shows the hardware environment that is assumed in the design.
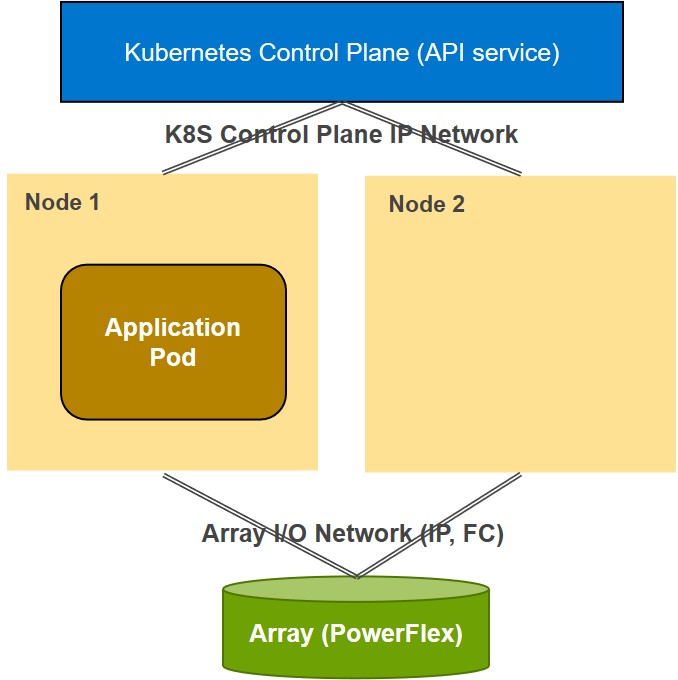
A Kubernetes Control Plane is assumed to exist that provides the K8S API service used by CSM for Resiliency. There is an arbitrary number of worker nodes (two are shown in the diagram) that are connected to the Control Plane through a K8S Control Plane IP Network.
The worker nodes (e.g. Node1 and Node2) can run a mix of CSM for Resiliency monitored Application Pods as well as unmonitored Application Pods. Monitored Pods are designated by a specific label that is applied to each monitored pod. The label key and value are configurable for each driver type when CSM for Resiliency is installed and must be unique for each driver instance.
The Worker Nodes are assumed to also have a connection to a Storage System Array (such as PowerFlex.) It is often preferred that a separate network be used for storage access from the network used by the K8S control plane, and CSM for Resiliency takes advantage of the separate networks when available.
Anti Use-Cases
CSM for Resiliency does not generally try to handle any of the following errors:
-
Failure of the Kubernetes control plane, the etcd database used by Kubernetes, or the like. Kubernetes is generally designed to provide a highly available container orchestration system, and it is assumed clients follow the standard and/or best practices in configuring their Kubernetes deployments.
-
CSM for Resiliency is generally not designed to take action upon a failure solely of the Application Pod(s). Applications are still responsible for detecting and providing recovery mechanisms should their application fail. There are some specific recommendations for applications to be monitored by CSM for Resiliency that are described later.
Failure Model
CSM for Resiliency’s design is focused on detecting the following types of hardware failures, and when they occur, moving protected pods to hardware that is functioning correctly:
-
Node failure. Node failure is defined to be similar to a Power Failure to the node which causes it to cease operation. This is differentiated from Node Communication Failures which require different treatments. Node failures are generally discovered by receipt of a Node event with a NoSchedule or NoExecute taint, or detection of such a taint when retrieving the Node via the K8S API.
Generally, it is difficult to distinguish from the outside if a node is truly down (not executing) versus if it has lost connectivity on all its interfaces. (We might add capabilities in the future to query BIOS interfaces such as iDRAC, or perhaps periodically writing to file systems mounted in node-podmon to detect I/O failures, in order to get additional insight as to node status.) However, if the node has simply lost all outside communication paths, the protected pods are possibly still running. We refer to these pods as “zombie pods”. CSM for Resiliency is designed to deal with zombie pods in a way that prevents them from interfering with replacement pods it may have made by fencing the failed nodes and when communication is re-established to the node, going through a cleaning procedure to remove the zombie pod artifacts before allowing the node to go back into service.
-
K8S Control Plane Network Failure. Control Plane Network Failure often has the same K8S failure signature (the node is tainted with NoSchedule or NoExecute). However, if there is a separate Array I/O interface, CSM for Resiliency can often detect that the Array I/O Network may be active even though the Control Plane Network is down.
-
Array I/O Network failure is detected by polling the array to determine if the array has a healthy connection to the node. The capabilities to do this vary greatly by array and communication protocol type (Fibre Channel, iSCSI, NFS, NVMe, or PowerFlex SDC IP protocol). By monitoring the Array I/O Network separately from the Control Plane Network, CSM for Resiliency has two different indicators of whether the node is healthy or not.
-
K8S Control Plane Failure. Control Plane Failure is defined as failure of kubelet in a given node. K8S Control Plane failures are generally discovered by receipt of a Node event with a NoSchedule or NoExecute taint, or detection of such a taint when retrieving the Node via the K8S API.
-
CSI Driver node pods. CSM for Resiliency monitors CSI driver node pods.If for any reason the CSI Driver node pods fail and enter the Not Ready state, it will taint the node with NoSchedule value. This will disable kubernetes scheduler to schedule new workloads on the given node, hence avoid workloads that needed CSI Driver pods to be in Ready state.
Feedback
Was this page helpful?
Thank you for your feedback!
Sorry to hear that. Please tell us how we can improve.