Disaster Recovery
Disaster Recovery Workflows
Once the DellCSIReplicationGroup & PersistentVolume objects have been replicated across clusters (or within the same cluster), users can exercise the general Disaster Recovery workflows.
Planned Migration to the target cluster/array
This scenario is the typical choice when you want to try your disaster recovery plan or you need to switch activities from one site to another:
a. Execute “failover” action on selected ReplicationGroup using the cluster name
./repctl --rg rg-id failover --target target-cluster-name
b. Execute “reprotect” action on selected ReplicationGroup which will resume the replication from new “source”
./repctl --rg rg-id reprotect --at new-source-cluster-name

Unplanned Migration to the target cluster/array
This scenario is the typical choice when a site goes down:
a. Execute “failover” action on selected ReplicationGroup using the cluster name
./repctl --rg rg-id failover --target target-cluster-name --unplanned
b. Execute “swap” action on selected ReplicationGroup which would swap personalities of R1 and R2 (only applicable for PowerMax driver)
./repctl --rg rg-id swap --at target-cluster-name
Note: Unplanned migration usually happens when the original “source” cluster is unavailable. The following action makes sense when the cluster is back.
c. Execute “reprotect” action on selected ReplicationGroup which will resume the replication.
./repctl --rg rg-id reprotect --at new-source-cluster-name
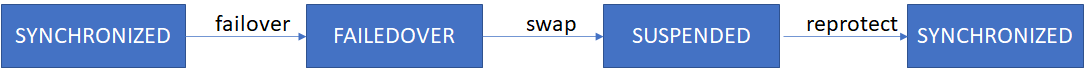
NOTE: When users do Failover and Failback, the tests pods on the source cluster may go “CrashLoopOff” state since it will try to remount the same volume which is already mounted. To get around this problem, bring down the number of replicas to 0 and then after that is done, bring it up to 1.